お買い得な株って何?
きっと実際の価値より安く買うことができる株だと思う。 そのような株は、やがて市場により正しく評価され、結果として利益につながるはずです。
でもずっと安く評価されている株もあるはずで、100年後に正しく評価されてもなぁ…。
ということで半年後ぐらいには正しく評価されるような株を見つけることを目標としたい。
(実際には半年は短く、もっと長い期間で考えるべきです。NISAならなおさら)
とにかくはじめます🍛
データを集める
とりあえず何はともあれ株のデータを集めます。
といってもすでに半年ほど前にWebスクレイピングにより収集したデータがあるのでそれを利用します。
なおスクレイピングの詳細はネット上にも山ほど情報があるため割愛しますが、 スクレイピングを行う上で法律・利用規約・マナーなどはしっかり守る必要はあります。
例えば以下のような事項です
- 法律:著作権を侵害しない。情報解析以外の目的で使用しない
- 利用規約:サイトの利用規約を守り、スクレイピングを禁止していれば実施しない
- マナー:過度な負荷をかけない。最悪、業務妨害となる。
データ内容
結局、手元に以下のようなデータを揃えました。
- 各銘柄の財務データ(約100項目)
- 決算日からその後半年間の平均株価
- 各銘柄ごとに過去数年分も含むためレコード数は約1万件
なお決算当時の株価ではなく半年間の平均株価を取得するしているのは、 決算日に財務データが公表されるわけでは無いからです。 そして決算日から半年間くらいは、 発表された業績が株価に反映されるかなぁという勝手な妄想によるものです。
実際には財務データが公表される時点である程度株価には織り込まれていますし、 株価は財務データ以外の影響も大きく受けるわけですが、そのあたりは考慮していません。
このあたりは次回もう少し詳しく述べます。
データ前処理
項目が100項目ほどあると解析が面倒なので、以下のような観点で項目は適当に絞りました。
- 欠損値が多い列
- 意味合いが近い(相関が高い)列
- その場合どちらの列を採用するかという問題はありますが、これも解析する上で私が分かりやすいと思う方を採用しました
その結果、項目数は30弱になりました。
なおここで項目を絞っている理由は、 あくまで人間にとって理解しやすくすることおよびリソースの問題で、 より良い予測モデルを作るためではないです。
実際に後ほど予測モデルを作りますが、全項目を利用したほうが全体の精度がやや良くなりました。ただその代わりに増加した学習時間や使用メモリの増加に見合うものではありませんでした。 (ちなみにそのあたりの特徴量エンジニアリングの話は今回のシリーズでは書きません)
相関図を描いてみる
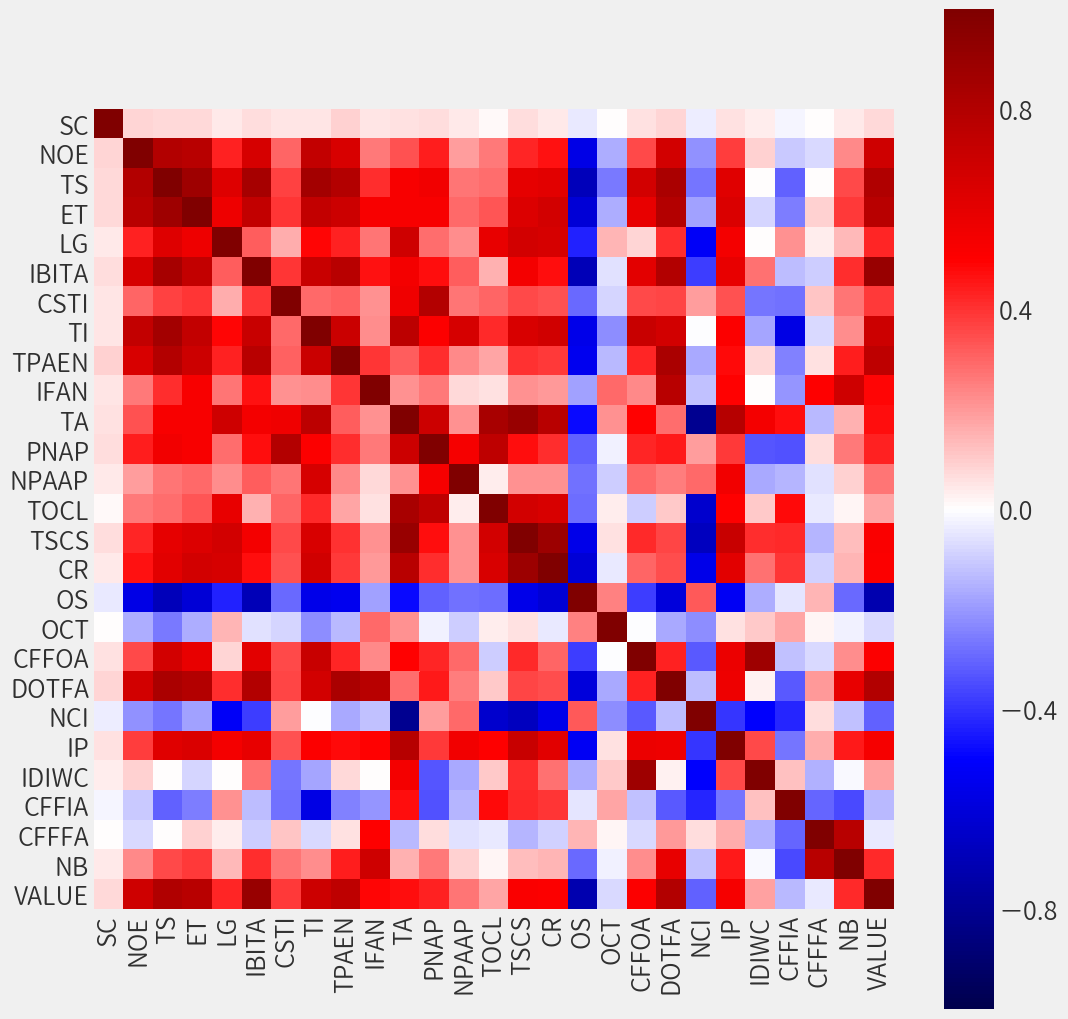
列名の英字は私が適当に付けました。以下は一例。
SC: 証券コードNOE: 従業員数TS: 売上高合計VALUE: 時価総額(株価×発行済株数)
時価総額と当期純利益に相関あり!?
相関図から時価総額VALUEと当期純利益IBITAは正の相関があることが分かります。
ただこの関係はまさにPERを表しており、
多くの投資家が参考にしている指標であるため、
相関があるのも納得できます。
PER = 時価総額 ÷ 当期純利益
つまりなんの目新しい発見では無いというわけです。
ということで最後は気休めにその様子をプロットして終わります。
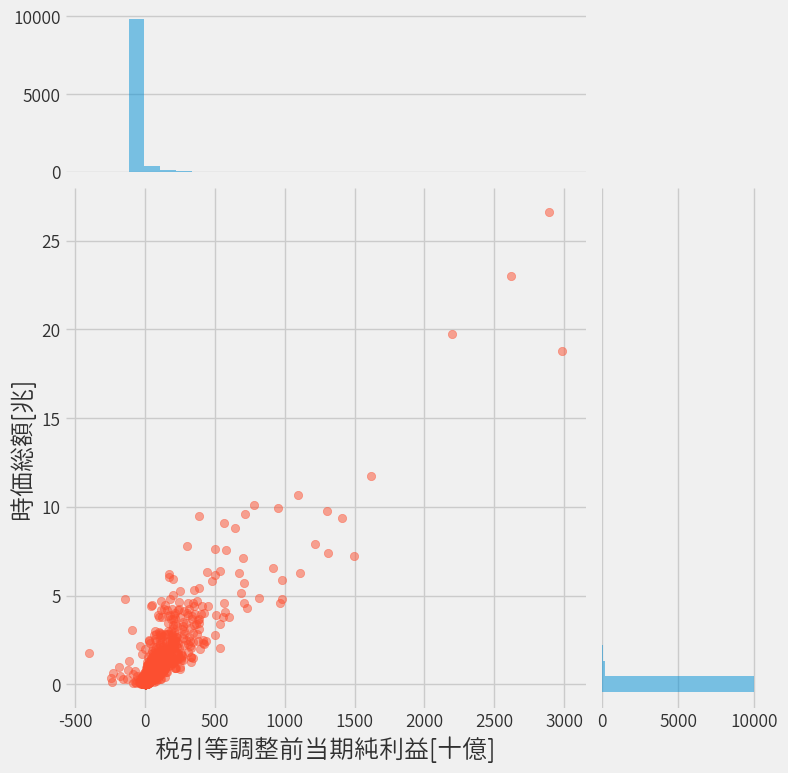
- 右上に突出しているのはトヨタですね
- 傾きが
PERになるはずなので、割安株は見つけられそうですね
分かりやすいようにLogスケールのプロットもしてみます。
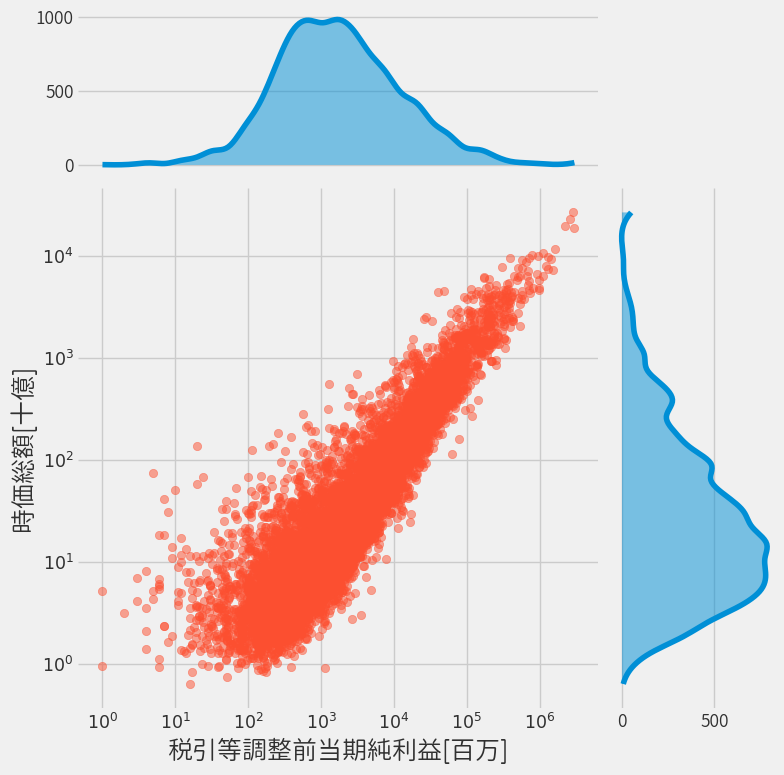
- 純利益マイナスの企業は除いてます
次回以降でお買い得な株を見つける方法を考えます。