グラフ理論
偉そうにグラフ理論を語れるほどの知識はありませんが、networkxでグラフを構築さえできれば、だいたいの概念を理解しておけば、用意された関数群を利用して様々な解析を行えます。
とにかくはじめます🍛
次数
ここでの次数とは、とある有名に対して接続されている辺の数です。1
つまり次数は有名人ごとに定義される数値であり、以下の場合であれば9となります。
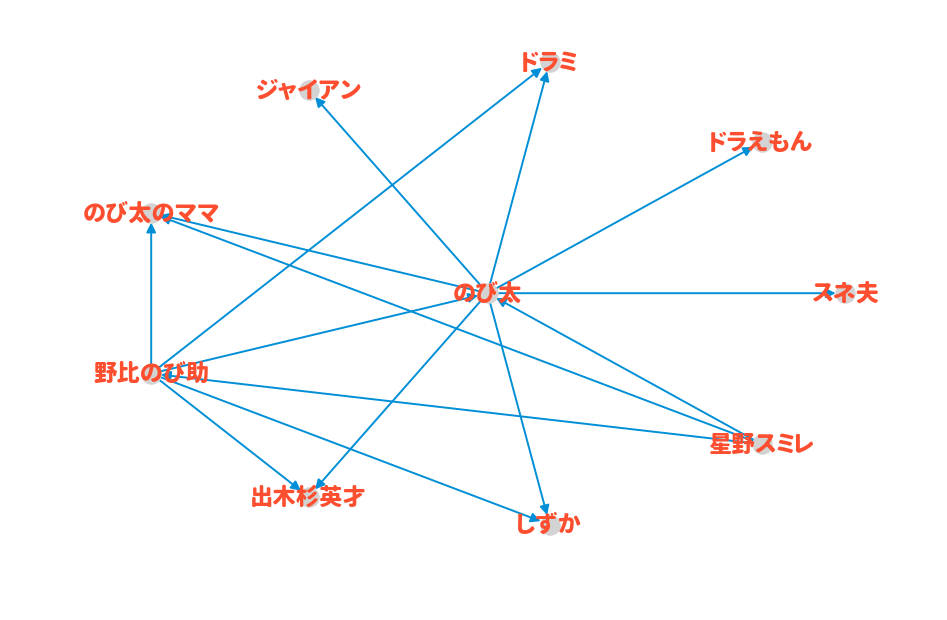
idx = n2i['のび太']
G.degree[idx]
# -> 9
次数が多ければ多いほど、他の有名人とのつながりが多いことを意味します。
なお上記は架空のサンプルでなく、実際の結果です。 つまり実在する人物以外でも、「他の人はこちらも検索」が表示されるのです。
開始地点は実在する人物(日本の有名人知名度のTOP100)だったので、どこからアニメキャラクターになったのかは気になります。 (それは別の記事で紹介します)
次数の分布
全有名人の次数を求めて、そのヒストグラムを描画します。
df = pd.DataFrame(G.degree, columns=['id', 'degree']).set_index('id')
plt.subplot(111, title='次数の分布', xlabel='次数', yscale='log')
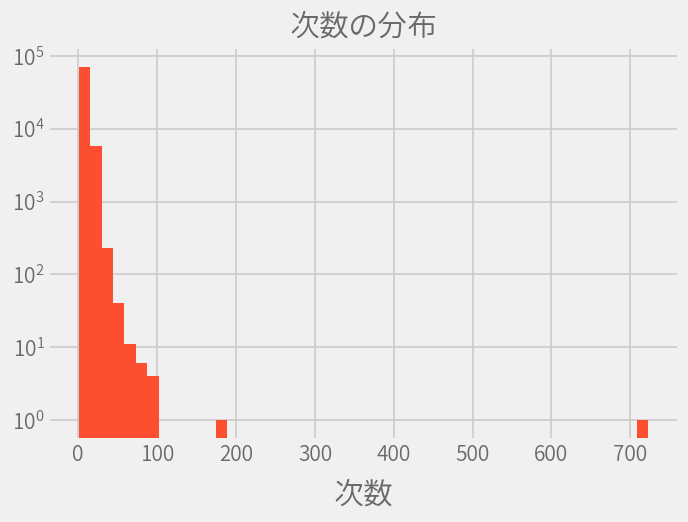
ずば抜けて次数の高い2名がいるので、次数100以下の結果も描画しておきます。
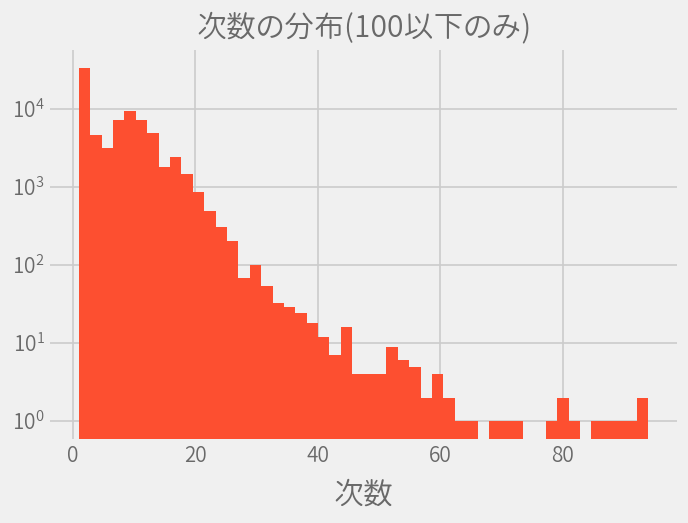
これより分かったことは
- 次数が多くなるほどその数も減っている
- 次数が1のデータがもっとも多い
- 次数が100を超える有名人が2人いる
次数のTOP10
| No | 有名人 | 次数 |
|---|---|---|
| 1 | 徳川家康 | 723 |
| 2 | 松本人志 | 184 |
| 3 | 指原莉乃 | 94 |
| 4 | 久保建英 | 93 |
| 5 | 坂本勇人 | 92 |
| 6 | 弘中綾香 | 89 |
| 7 | 土屋太鳳 | 87 |
| 8 | 窪田正孝 | 85 |
| 9 | 辻希美 | 81 |
| 10 | 小栗旬 | 80 |
徳川家康の圧倒的な存在感。
徳川家康とつながりがある有名人は、いわゆる芸能人ではなく学者や歴史上の人物などが多くを占めています。 よってこの結果はいつ調査したかでも大きく変わりますが、徳川家康に関してはいつ調査しても強いと思われます。
松本人志さんの強さを感じる一方で、途中で探索を打ち切っていることもあり、3位以下は誤差の範囲と考えても良いかもしれません。
# コード例
df.sort_values(
'degree',
ascending=False)[:10].assign(
name=lambda x:x.index.map(lambda x:i2n[x]))
徳川家康
次数が最も多い徳川家康と直接つながりのある有名人を描画するとこんな感じです。
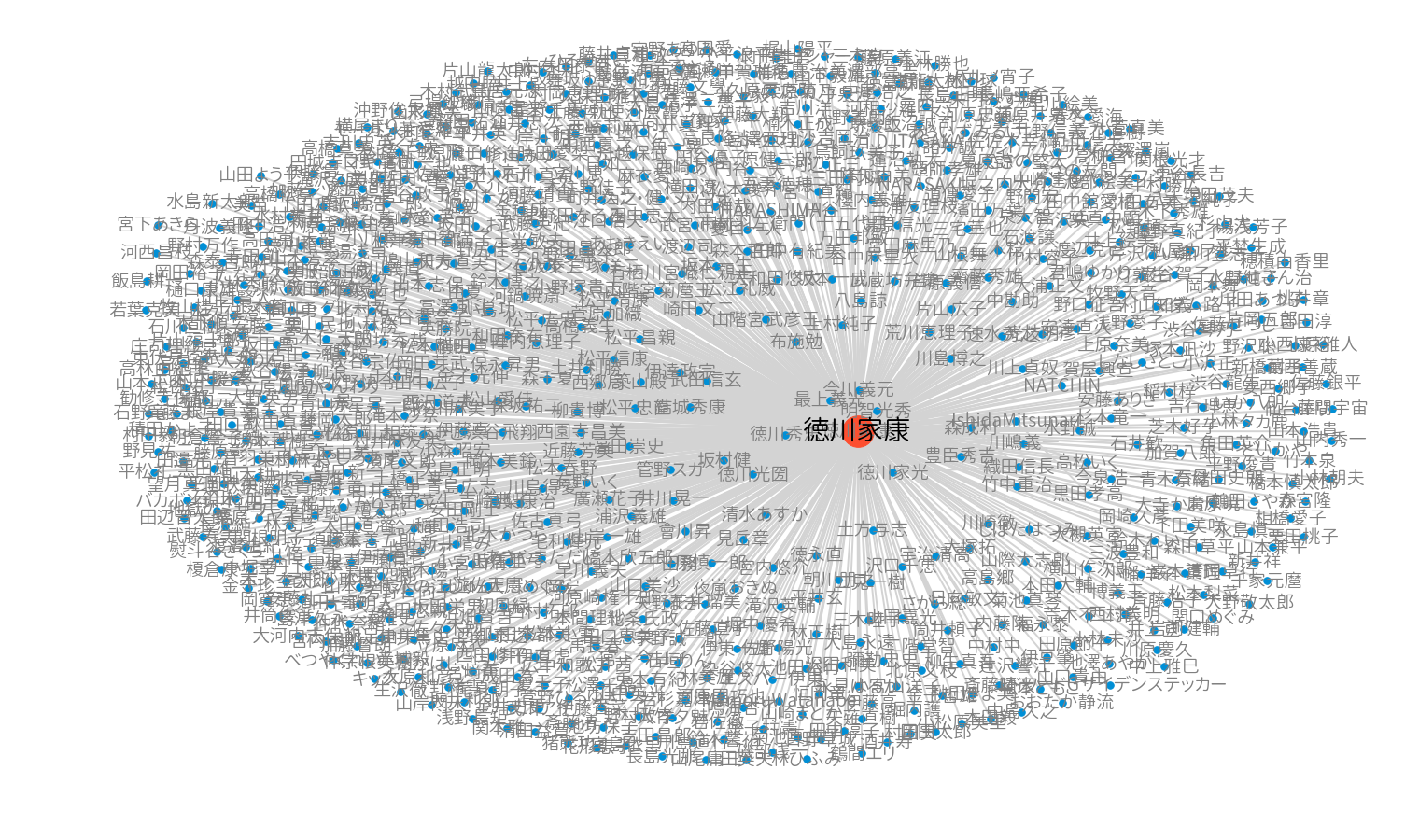
次数50以上で可視化
次数が50より大きい有名人は48名いました。 この程度であれば可視化できそうなので、以下の条件で描画した結果が以下です。
- 辺は無方向グラフに変換した場合の有名人同士の近さを幅と色の濃さで表現
- 近さは最短経路でshortest_path_lengthにより算出
- 頂点は次数の大きさで表現
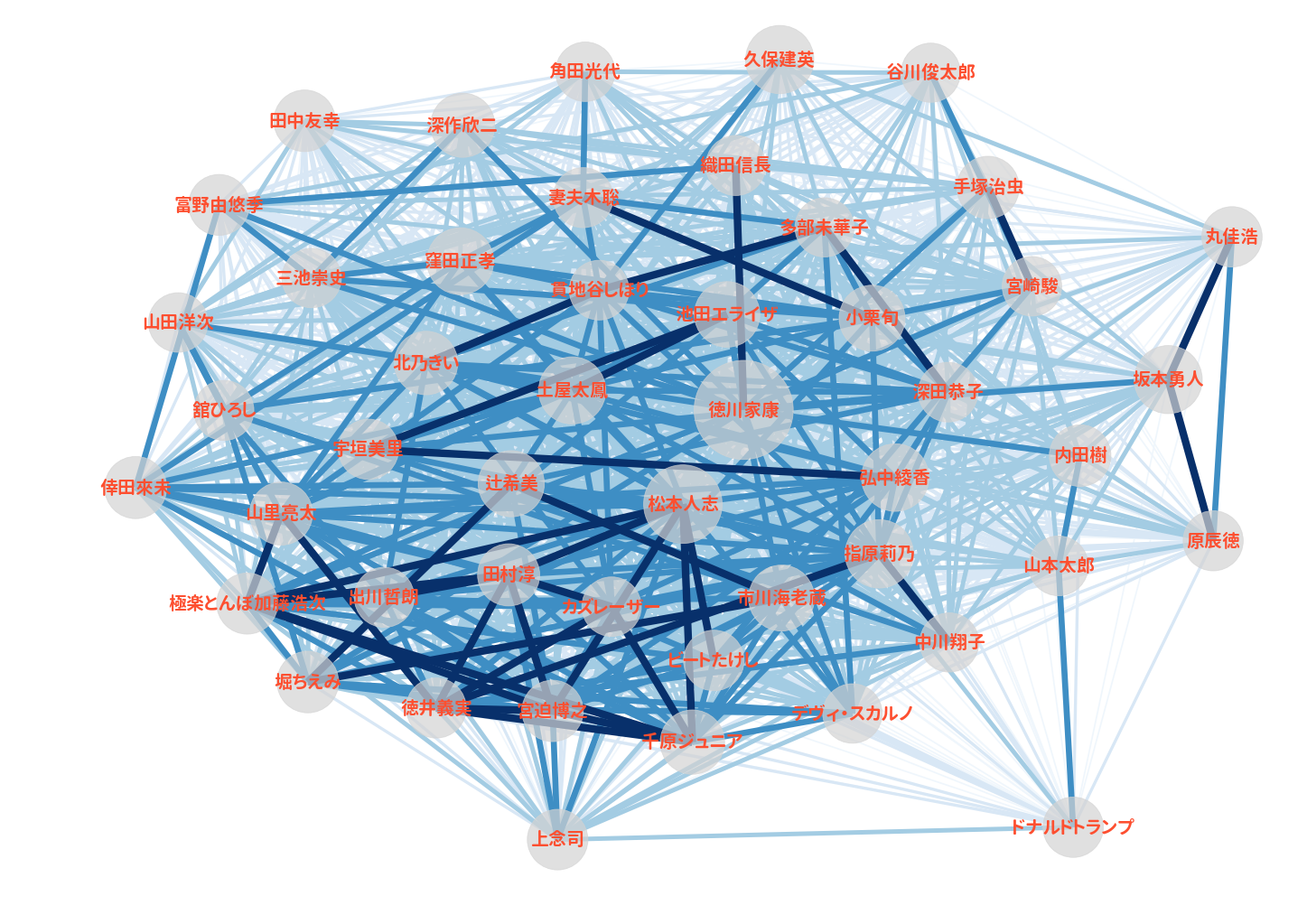
図はspring_layoutで配置していた結果ですが、ドナルド・トランプさんだけが少しつながりが希薄なため、集団の外にはみ出ていることが分かります。
またお笑い芸人の方々によって、強くつながっている集団が下の方に観察できます。 これは開始地点の人物(日本の有名人知名度のTOP100)に、そもそもお笑い芸人さんが多いことも関係していそうです。
それ以外にも役者やスポーツ選手など、比較的固まって描画されていることも見て取れます。
[参考] 辺の重なりについて
少しnetworkxの話も。
実は辺の重なりは追加した順に描画されないようで、普通に描画すると以下のようにごちゃごちゃした印象になります。
weight = [v[-1] for v in g.edges.data('weight')]
nx.draw_networkx_edges(g, pos=pos, edge_color=weight, edge_cmap=cm.Blues, width=np.array(weight)*5)
よって重みが大きい辺ほど手前に描画されるため、1本ずつ重ねて描画することで回避しています。
m = cm.ScalarMappable(norm=norm, cmap=cm.Blues)
weight = sorted(g.edges.data('weight'), key=lambda x: x[2])
for x, y, v in weight:
nx.draw_networkx_edges(g, edgelist=[(x, y)], pos=pos, edge_color=[m.to_rgba(v)], width=v*5)
中心性
中心性とはノードの重要性を評価するための指標であり、計算方法もいくつか存在します。
networkxでもあらかじめ中心性を求める関数がいくつか定義されています。 Centrality - NetworkX 2.4 documentation
次数中心性
これは上述した次数が大きいほど有名人ほど重要だと考えた指標です。 なので次数中心性の結果もさきほどの次数の大きい有名人と一致します。
# 次数中心性のTOP5
{i2n[k]:v for k,v in sorted(nx.degree_centrality(G).items(), key=lambda x:x[1], reverse=True)[:5]}
| 有名人 | 次数中心性 |
|---|---|
| 徳川家康 | 0.0093 |
| 松本人志 | 0.0024 |
| 指原莉乃 | 0.0012 |
| 久保建英 | 0.0012 |
| 坂本勇人 | 0.0012 |
媒介中心性
「他の人はこちらも検索」で辿っていく場合に、あらゆる経路上にもっとも頻繁に現れる有名人を重要とする指標です。 あらゆる有名人を媒介する仲介者のような存在なので、たしかに重要と言えるかもしれません。
# 媒介中心性のTOP5
{i2n[k]:v for k, v in sorted(nx.betweenness_centrality(G).items(), key=lambda x:x[1], reverse=True)[:5]}
| 有名人 | 媒介中心性 |
|---|---|
| 大谷翔平 | 0.0131 |
| 岸惠子 | 0.0102 |
| イヴ・シャンピ | 0.0098 |
| 北乃きい | 0.0092 |
| 忽那汐里 | 0.0092 |
次数中心性とは全くことなる結果になりました。 大谷翔平さんはバッターとピッチャー、日本とアメリカなどあらゆる分野を結びつける重要人物なのかもしれません。(適当)
近傍中心性
他の有名人との距離の総和が小さいほど重要だと考える指標です。
# 近傍中心性のTOP5
{i2n[k]:v for k, v in sorted(nx.closeness_centrality(G).items(), key=lambda x:x[1], reverse=True)[:5]}
| 有名人 | 近傍中心性 |
|---|---|
| 徳川家康 | 0.081 |
| 池田エライザ | 0.078 |
| 北乃きい | 0.077 |
| 小栗旬 | 0.076 |
| 上白石萌音 | 0.076 |
徳川家康を除き、やはり次数中心性とも異なる結果が得られました。 彼らは「他の人はこちらも検索」で辿った場合に、あらゆる有名人に対して平均的に早くたどり着ける人たちです。
ページランク
媒介中心性も近傍中心性も、誰に参照されているか、誰を参照しているかが大きく影響を与えます。
一方で次数中心性は単独の指標となっているため、結果に差異が出たと思われます。
そこでより次数の大きい有名人と繋がっている人は、やはり重要と考える指標がページランクです。 グーグルの検索順位を決めるアルゴリズムとしても有名です。
{i2n[k]:v for k, v in sorted(nx.pageranks(G).items(), key=lambda x:x[1], reverse=True)[:5]}
| 有名人 | ページランク |
|---|---|
| 徳川家康 | 0.00162 |
| 松本人志 | 0.00073 |
| 豊臣秀吉 | 0.00055 |
| 織田信長 | 0.00052 |
| 池田エライザ | 0.00050 |
圧倒的な次数を持つ徳川家康とつながっている人物が上位へ上がってきました。
まとめ
総合的には徳川家康が非常に影響力を持っているように感じました。
しかしながら私としては、ページランクで5位、近傍中心性で2位となった池田エライザさんの存在が気になってしょうがありません。 よってこれからはその活躍に注目していきたいと思います。

参考URL
- 日本の中心はどの県だ?グラフ理論(ネットワーク)の基本的な諸概念 - アジマティクス
- グラフ・ネットワーク分析で遊ぶ(3):中心性(PageRank, betweeness, closeness, etc.) - 渋谷駅前で働くデータサイエンティストのブログ
- 池田エライザ オフィシャルウェブサイト / Ikeda Elaiza official website